
![]()
현재 진행하는 프로젝트에서 대규모 트래픽 처리를 어떻게 할지 고민해보았다. 코드 최적화, 규모 확장, 로드밸런서 도입 등의 방법들이 있지만, 이번에는 캐시 서버 도입에 대해, 그 중에서도 Redis에 대해 알아보려고 한다. 캐시 서버는 무엇이며 왜 대규모 트래픽 처리에 사용되는지, 또 Redis는 어떤 특징을 가지고 있는지를 하나씩 기록해 보자.
캐시 서버란?
먼저 캐시란, 자주 사용하는 데이터나 연산의 결과값을 좀 더 접근하기 쉬운 곳에 미리 복사해 놓고, 필요할 때마다 빠르게 꺼내 쓸 수 있도록 하는 저장소를 말한다. 컴퓨터에서는 읽는 속도가 느린 디스크의 데이터를, 읽는 속도가 빠른 메모리로 가져와서 메모리상에서 읽고 쓰며 컴퓨터의 성능을 향상시킨다.
캐시 서버도 마찬가지다. 이미 처리된 적 있는 쿼리의 결과를 캐시 서버에 저장해놓고, 같은 쿼리가 호출될 때마다 쿼리를 실행하지 않고 그 결과를 가져오기만 한다면 응답을 훨씬 빠르게 줄 수 있게 된다.
때문에 대규모 트래픽을 처리하는데 캐시 서버가 필요한 것이다. 만약 캐시 서버가 없다면, 데이터를 조회할 때 ORM을 통해 DB에 모든 요청에 대한 쿼리가 나가게 되는데, 동시 사용자수가 증가해 요청이 많아지면 그만큼 쿼리가 많아지고 DB에 부하가 커져 서비스가 느려지게 되기 때문이다.
캐시 전략
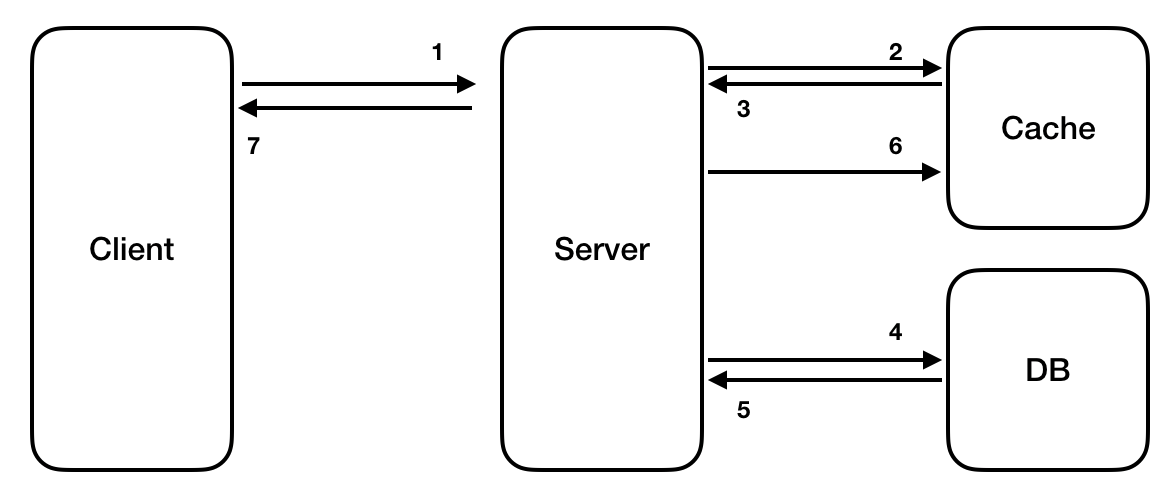
Look aside Cache
![]()
- 클라이언트는 서버에 데이터 조회 요청을 보낸다.
- 웹 서버는 캐시에 해당 요청 결과값이 존재하는지 확인한다.
- 캐시는 조회 결과를 반환한다.
- 존재 한다면 7번으로
- 존재 하지 않는다면 4번으로
- 웹 서버는 DB에 데이터가 존재하는지 확인한다.
- DB는 조회 결과를 반환한다.
- 웹 서버는 DB의 결과 값을 캐시에 저장한다.
- 웹 서버는 클라이언트에게 데이터 조회에 대한 응답을 보낸다.
Write Back
- 웹 서버는 저장할 모든 데이터를 캐시에 쌓아둔다.
- 특정 시점에 쌓여있는 모든 데이터를 한번에 DB에 저장한다.
- 저장이 완료되면 캐시를 비워 캐시에 쌓인 데이터를 삭제한다.
Redis란?
Redis(REmote DIctionary Server)는 Remote(원격)에 위치하고 프로세스로 존재하는 In-Memory 기반의 Dictionary(key-value) 구조 데이터 관리 Server 시스템이다.

Dictionary 구조, 즉, 데이터를 ‘키-값’ 형태로 단순하게 저장하기 때문에, 관계형 데이터베이스처럼 쿼리 연산을 지원하지는 않지만, 대신 데이터의 고속 읽기와 쓰기에 최적화 되어 있다.
또, Redis는 인 메모리(In-Memory) DB로, 일반 데이터베이스 같이 디스크(ssd)에 데이터를 쓰는 구조가 아니라 메모리(dram)에서 데이터를 처리하기 때문에 작업 속도가 상당히 빠르다. 하지만, 데이터가 메모리에만 저장되어 있기 때문에, 백업 옵션을 두지 않았다면, 오류로 캐시에 장애가 발생했을 때 저장되지 않은 데이터는 유실될 위험이 있다.
Redis의 특징
- List, Set, Sorted Set, Hash 등과 같은 Collection을 지원한다.
- Collection 들에 대한 읽기/쓰기 작업이 O(1)의 성능을 보장한다.
- Redis는 Single Thread를 사용한다.
- Context Switching 에 대한 비용을 줄일 수 있다.
- Race condition에 빠지는 것을 방지한다.
- 하지만 긴 시간을 요하는(long-time) 명령어 수행시 다른 명령어들을 처리 할 수 없는 상태가 되어 비효율적으로 동작하게 된다.
- Redis Cluster를 구성해 데이터 분산 처리를 할 수 있다.
- 데이터를 여러 노드로 분산시켜 사용 메모리를 분산할 수 있다.
- Redis Sentinel과 Redis Replication으로 장애 진단 및 복구를 할 수 있다.
- Master - Slave의 Replication으로 구성하고, Master에서 장애가 발생하면 Slave를 Master로 승격시켜 복구한다.